Why not adopt me?
NAME
WebAPI::DBIC
VERSION
version 0.001008
DESCRIPTION
WebAPI::DBIC provides the parts you need to build a feature-rich RESTful JSON web service API backed by DBIx::Class schemas.
WebAPI::DBIC features include:
* Use of the JSON+HAL (Hypertext Application Language) lean hypermedia type
* Automatic detection and exposure of result set relationships as HAL _links
* Supports safe robust multi-related-record CRUD transactions
* Built on the strong foundations of Web::Machine and Plack, with Path::Router as the router. (We aim to support other routers soon.)
* Built as fine-grained roles for maximum reusability and extensibility
* Integrates with other Plack based applications.
* The resource roles can be added to your existing application
* A built-in copy of the generic HAL API browser application
* An example .psgi file that gives you an instant web service for any DBIx::Class schema
HAL - Hypertext Application Language
The Hypertext Application Language hypermedia type (or HAL for short) is a simple JSON format that gives a consistent and easy way to hyperlink between resources in your API.
Adopting HAL makes the API explorable, and its documentation easily discoverable from within the API itself. In short, it will make your API easier to work with and therefore more attractive to client developers.
A JavaScript "HAL Browser" is included in the WebAPI::DBIC distribution. (WebAPI::DBIC doesn't yet offer direct support for documentation resources.)
APIs that adopt HAL can be easily served and consumed using open source libraries available for most major programming languages. It's also simple enough that you can just deal with it as you would any other JSON.
See http://stateless.co/hal_specification.html for more details.
Web::Machine
The Web::Machine module provides a RESTful web framework modeled as a formal state machine. This is a rigorous and powerful approach, originally developed in Haskel and since ported to many other languages.
See https://raw.githubusercontent.com/basho/webmachine/develop/docs/http-headers-status-v3.png for an image of the state machine.
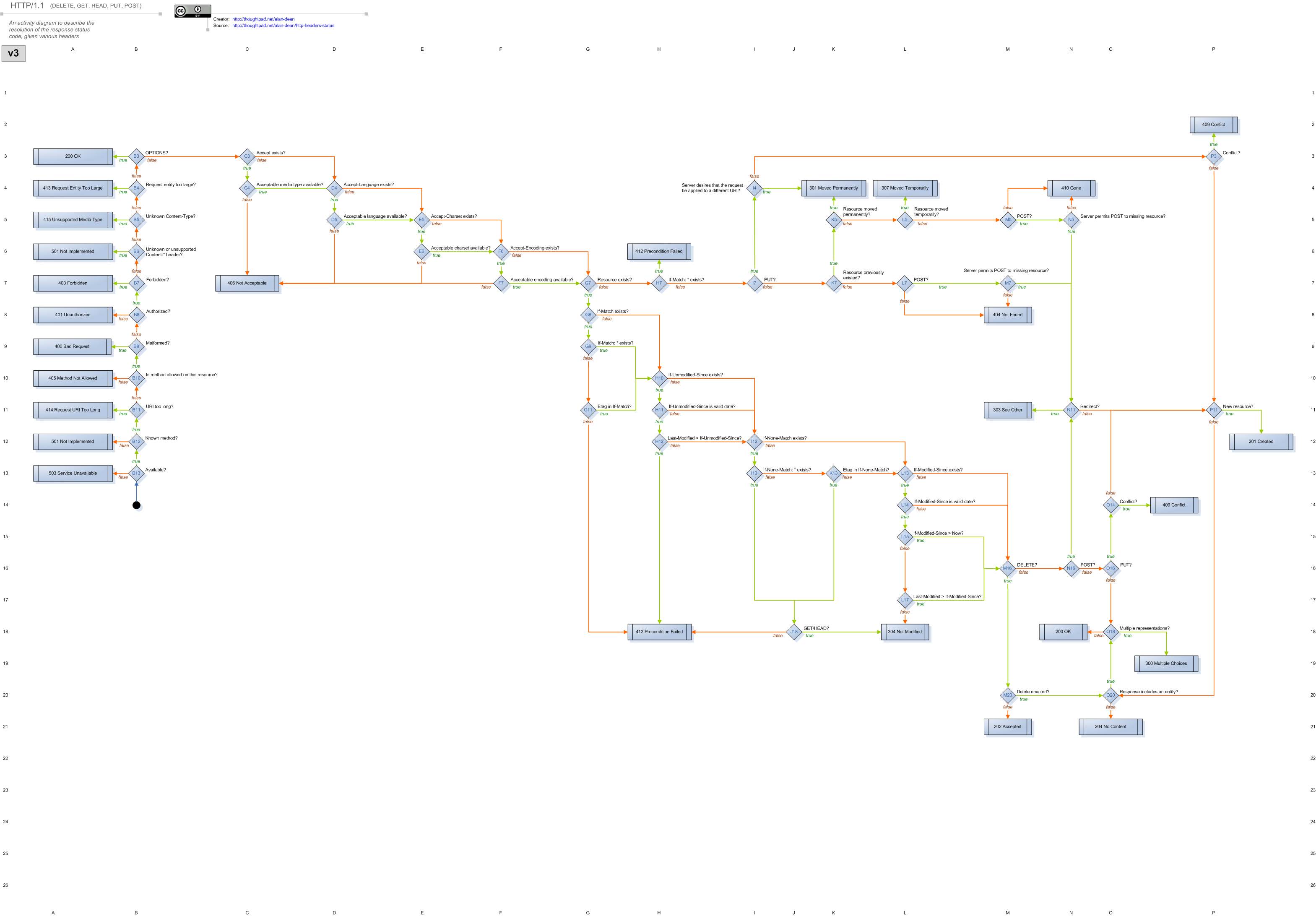{kind=link}
By building on Web::Machine, WebAPI::DBIC removes the need to implement all the logic needed for accurate and full-features HTTP protocol behaviour. You just provide small pieces of logic at the decision points you care about and Web::Machine looks after the rest.
See https://github.com/basho/webmachine/wiki for more information.
Web::Machine provides the logic to handle a HTTP request for a single resource.
With WebAPI::DBIC those resources typically represent a DBIx::Class result set, a row, or a method invocation on a row. They are implemented as a subclass of Web::Machine::Resource that consumes a some set of WebAPI::DBIC roles that add the specific desired functionality.
Path::Router
The Path::Router module is used to organize multiple resources into a URL namespace. It's used to route incoming requests to the appropriate Web::Machine instance. It's also used in reverse to construct links to other resources that are included in the outgoing responses.
Path::Router supports full reversability: the value produced by a path match can be passed back in and you will get the same path you originally put in. This removes ambiguity and reduces mis-routings. This is important for WebAPI::DBIC because, for each resource returned, it automatically add HAL _links containing the URLs of the related resources, as defined by the DBIx::Class schema. This is what makes the API discoverable and browseable.
NAME
WebAPI::DBIC - A composable RESTful JSON+HAL API to DBIx::Class schemas using roles and Web::Machine
STATUS
The WebAPI::DBIC code has been in production use since early 2013, however it's only recently been open sourced (July 2014) so it's still lacking in documentation.
It's also likely to undergo a period of refactoring now there are more developers contributing and the code is being applied to more domains.
Interested? Please get involved! See "HOW TO GET HELP" below.
QUICK START
To demonstrate the rich functionality that the combination of DBIx::Class and HAL provides, the WebAPI::DBIC framework includes a ready-to-use Plack .psgi file that provides an instant web data service for any DBIx::Class schema.
$ git clone https://github.com/timbunce/WebAPI-DBIC.git
$ cd WebAPI-DBIC
$ cpanm Module::CPANfile
$ cpanm --installdeps . # this may take a while
$ export WEBAPI_DBIC_SCHEMA=DummyLoadedSchema
$ plackup -Ilib -It/lib webapi-dbic-any.psgi
... open a web browser on port 5000 to browse the APIThen try it out with your own schema:
$ export WEBAPI_DBIC_SCHEMA=Foo::Bar # your own schema
$ export WEBAPI_DBIC_HTTP_AUTH_TYPE=none # recommended
$ export DBI_DSN=dbi:Driver:... # your own database
$ export DBI_USER=... # for initial connection, if needed
$ export DBI_PASS=... # for initial connection, if needed
$ plackup -Ilib webapi-dbic-any.psgi
... open a web browser on port 5000 to browse your new APIThe API is read-only by default. To enable PUT, POST, DELETE etc, set the WEBAPI_DBIC_WRITABLE environment variable.
MODULES
Roles
WebAPI::DBIC::Resource::Role::DBIC is responsible for interfacing with DBIx::Class, 'rendering' individual records as resource data structures. It also interfaces with Path::Router to handle relationship linking.
WebAPI::DBIC::Resource::Role::SetRender is responsible for rendering an entire result set as either plain JSON or JSON+HAL by iterating over the individual items. For JSON+HAL it adds the paging links.
WebAPI::DBIC::Resource::Role::Set is responsible for accepting GET and HEAD requests for set resources (collections) and returning the results as JSON or JSON+HAL.
WebAPI::DBIC::Resource::Role::SetWritable is responsible for accepting POST request for set resources. It handles the recursive creation of related records. Related records can be nested to any depth and are created from the bottom up within a transaction.
WebAPI::DBIC::Resource::Role::Item is responsible for GET and HEAD requests for single item resources and returning the results as JSON or JSON+HAL.
WebAPI::DBIC::Resource::Role::ItemWritable is responsible for accepting PUT and DELETE requests for single item resources. It handles the recursive update of related records. Related records can be nested to any depth and are updated from the bottom up within a transaction. Handles both 'PUT is replace' and 'PUT is update' logic.
WebAPI::DBIC::Resource::Role::ItemInvoke is responsible for accepting POST requests for single item resources representing the invocation of a specific method on an item (e.g. POST /widget/42/invoke/my_method_name?args=...).
WebAPI::DBIC::Resource::Role::DBICAuth is responsible for checking authorization to access a resource. It currently supports Basic Authentication, using the DBI DSN as the realm name and the return username and password as the username and password for the database connection.
WebAPI::DBIC::Resource::Role::DBICParams is responsible for handling request parameters related to DBIx::Class such as page, rows, order, me, prefetch, fields etc.
Utility Roles
WebAPI::DBIC::Role::JsonEncoder provides encode_json() and decode_json() methods.
WebAPI::DBIC::Role::JsonParams provides a param() method that returns query parameters, except that any parameters with names that have a ~json suffix have their values JSON decoded, so they can be arbitrary data structures.
Resource Classes
To make building typical applications easier, WebAPI::DBIC provides four pre-defined resource classes:
WebAPI::DBIC::Resource::GenericCore is a base class that consumes all the general-purpose resource roles.
WebAPI::DBIC::Resource::GenericItem subclasses GenericCore and consumes extra roles for resources represented by an individual DBIx::Class row.
WebAPI::DBIC::Resource::GenericSet subclasses GenericCore and consumes extra roles for resources represented by a DBIx::Class result set.
WebAPI::DBIC::Resource::GenericItemInvoke subclasses GenericCore and consumes extra roles for resources that represent a specific method call on an item resource.
These classes are very simple because all the work is done by the various roles they consume. For example, here's the entire code for WebAPI::DBIC::Resource::GenericCore:
package WebAPI::DBIC::Resource::GenericCore;
use Moo;
extends 'WebAPI::DBIC::Resource::Base';
with 'WebAPI::DBIC::Role::JsonEncoder',
'WebAPI::DBIC::Role::JsonParams',
'WebAPI::DBIC::Resource::Role::Router',
'WebAPI::DBIC::Resource::Role::Identity',
'WebAPI::DBIC::Resource::Role::Relationship',
'WebAPI::DBIC::Resource::Role::DBIC',
'WebAPI::DBIC::Resource::Role::DBICException',
'WebAPI::DBIC::Resource::Role::DBICAuth',
'WebAPI::DBIC::Resource::Role::DBICParams',
;
1;and WebAPI::DBIC::Resource::GenericItem:
package WebAPI::DBIC::Resource::GenericSet;
use Moo;
extends 'WebAPI::DBIC::Resource::GenericCore';
with 'WebAPI::DBIC::Resource::Role::SetRender',
'WebAPI::DBIC::Resource::Role::Set',
'WebAPI::DBIC::Resource::Role::SetWritable',
;
1;Other Classes
A few other classes are provided:
WebAPI::DBIC::Util.pm provides a few general utilities.
WebAPI::DBIC::WebApp - this is the main app class and is most likely to change in the near future so isn't documented much yet.
TRANSPARENCY
WebAPI::DBIC aims to be a fairly 'transparent' layer between your DBIx::Class schema and the JSON that's generated and received.
So it's the responibility of your schema to return data in the format you want in your generated URLs and JSON, and to accept data in the format that arrives in requests from clients.
For an example of how to handle dates using DateTime nicely, see:
https://blog.afoolishmanifesto.com/posts/solution-on-how-to-serialize-dates-nicely/COMPARISONS
This section provides links to similar modules with a few notes about how they differ from WebAPI::DBIC.
... others? ...
App::AutoCRUD
App::AutoCRUD provides an automatically generated HTML interface to a database, including search forms. It can export data in various formats including JSON but isn't designed as a JSON API, so it's not directly comparable to WebAPI::DBIC. See also RapidApp.
App::AutoCRUD doesn't use DBIx::Class, it uses DBIx::DataModel (a UML-based ORM framework), but creates the model on the fly. That doesn't let you build business logic into the schema model the way you can with DBIx::Class.
RapidApp
To quote the documentation: RapidApp is an extension to Catalyst - the Perl MVC framework. It provides a feature-rich extended development stack, as well as easy access to common out-of-the-box application paradigms, such as powerful CRUD-based front-ends for DBIx::Class models, user access and authorization, RESTful URL navigation schemes, pure Ajax interfaces with no browser page loads, templating engine with front-side CMS features, declarative configuration layers, and more.
It's not designed as a JSON API and doesn't use HAL, so it's not directly comparable to WebAPI::DBIC.
INTEGRATIONS
This section provides information on how to integrate WebAPI::DBIC with existing applications.
Catalyst
As with any PSGI application, WebAPI::DBIC can integrate into Catalyst fairly simply with Catalyst::Action::FromPSGI. Here's an example integration:
package MyApp::Controller::HelloName;
use base 'Catalyst::Controller';
sub api : Path('/api') ActionClass('FromPSGI') {
my ($self, $c) = @_;
WebAPI::DBIC::WebApp->new({
schema => $c->model('DB')->schema,
writable => 0, # set true if desired
http_auth_type => 'none', # will use Catalysts' auth for the given path
# consider leveraging chaining or another
# ActionRole for auth
})->to_psgi_app
}Dancer
I'd welcome any information you could contribute here.
Mojolicious
I'd welcome any information you could contribute here.
...
HOW TO GET HELP
IRC: irc.perl.org#webapi
(click for instant chatroom login)
See also https://metacpan.org/pod/distribution/WebAPI-DBIC/NOTES.pod and https://github.com/timbunce/WebAPI-DBIC/issues
If there's anything you specifically need, just ask!
CREDITS
Stevan Little gets top billing for creating Web::Machine and Path::Router (not to mention Moose and much else besides).
Matt Trout and Peter Rabbitson and the rest of the DBIx::Class team for creating and maintaining such an excellent object <-> relational mapper.
Arthur Axel "fREW" Schmidt, both for his original "drinkup" prototype using Web::Machine that WebAPI::DBIC is based on, and for offering to help with the work required to open source and release WebAPI::DBIC to CPAN. Without that, and further help from Fitz Elliott, WebAPI::DBIC might still be a closed source internal project.
OVERVIEW OF REPRESENTIONS AND ACTIONS
The docs below are from old internal documentation. They're a bit rought and will be reworked and found a better home. They're here for now because they are useful to give a sense of how the API works and what it supports.
GENERIC ENTITY REPRESENTIONS
Here we define the default behavior for GET, PUT, DELETE and POST methods on item and set resources.
In these examples the ~ symbol is used to represent a common prefix. The prefix is intended to contain at least a single path name element plus a version number element, for example, in:
GET ~/ecosystems/the ~ represents a prefix such as "/clients/v1", so the above is a shorthand way of representing:
GET /clients/v1/ecosystems/Conventions
Resource names are typically plural nouns, and lower case, with underscores if required. Verbs could be used for for non-resource requests and might be capitalized (e.g. /Convert?from=Y&to=Y).
A parameter that's part of the url is represented in these examples with the :name convention, e.g. :id.
XXX That might change to the 'URL Template' RFC6570 style http://tools.ietf.org/html/rfc6570
GET Item
GET ~/resources/:idreturns
{
_links: { ... } # optional
_embedded: { ... } # optional
_meta: { ... } # optional
... # data attributes, optional
}The optional _links object holds relevant links in the HAL format (see below). This enables interactive browsing of the API.
The optional _embedded object holds embedded resources in the HAL format. (see "prefetch").
The optional _meta attribute might include things like the name of the attribute to treat as the label, or a count of items matching a search.
GET ~/ecosystems/1would include
{
id: 1,
...
person_id: 2, # foreign key
...
_links {
self: {
href: "/ecosystems/1"
},
"relation:person": {
href: /person/19
},
"relation:email_domain": {
href: "/email_domain/8"
}
},
}The "relation" links describe the relationships this resource has with other resources.
Currently only 1-1 relationships (e.g., belongs_to) are and simple 1-N (has_many) relationships are supported and get _links. Also see "prefetch".
GET Item - Optional Parameters
prefetch
prefetch=relationship
prefetch=relationship1,relationship2The prefetch parameter enables one or more related resources to be fetched and embedded in the response. For example:
GET ~/ecosystems/1?prefetch=personwould return:
{
id: 1,
person_id: 2, # foreign key
...
_links: { ... },
_embedded: {
person: { # prefetched using person_id
id: 2,
...
_links: { ... },
},
}
}Here the _embedded person is a resource, not an array of resources, because the relationship is 1-1. For 1-N relationships the value of the _embedded key would be an array that contains the relevant resource records.
fields
Partial responses:
fields=field1,field2XXX Currently doesn't work for limiting the fields of prefetched relations.
with
The with parameter is used to control optional items within responses. It's a comma separated list of words. This parameter is only passed-through in paging links.
* count
Adds a count attribute to the _meta hash in the results containing the count of items in the set matched by the request, i.e., the number of items that would be returned if paging was disabled. Also adds a last link to the _links section of the results.
* nolinks
TBD - possibly used to disable links in the results, especially for large sets of small items where the links section would take significant time and space to construct and return. Might be better as a linkdepth=N where N is decremented at each level of embedding so linkdepth=0 disables all links, but linkdepth=1 allows paging of the set but doesn't include links in the embedded resources.
GET on Set
GET ~/ecosystemsreturns
{
_links: { ... }, # optional
_meta: { ... }, # optional
_embedded: {
ecosystems => [
{ ... }, ...
]
}
}The _embedded object contains a key matching the resource name whoose value is an array of those resources, in HAL format. It may seem unusual that the response isn't simply an array of the resources, but you can think of the 'set' as a 'virtual' entity that contains nothing itself but just acts as a container, or view, for a set of embedded resources.
The _links objects would include links in HAL format for first/prev/next/last.
The _meta could include attributes like limit, offset.
GET on Set - Optional Parameters
Paging
Set results are returned in pages to prevent accidentally trying to fetch very large numbers of rows. The default is a small number.
rows=N - default 30 (at the time of writing)
page=N - default 1fields
Partial results, as for GET Item above.
Ordering
order=field1
order=field1 desc
order=field1 asc,field2 ascA comma-separated list of one or more ordering clauses, each consisting of a field designator followed by an optional direction. Direction can be asc or desc and defaults to asc.
Field names can refer to fields of "prefetch" relations. For example:
~/ecosystems_people?prefetch=person,client_auth&order=client_auth.usernameFiltering
?me.fieldname=valueFiltering with query params
?me.color=red&me.state=runningThe me.*= values can be JSON data structures if the field name is sufixed with ~json, for example:
?me.color~json=["red","blue"] # would actually be URL encodedwhich would be evaluated as an SQL 'IN' expression:
color IN ('red', 'blue')More complex expressions can be expressed using hashes, for example:
?me.color~json={"like":"%red%"} # would actually be URL encodedwould be evaluated as
color LIKE '%red%'and
?me.foo~json=[ "-and", {"!=":2}, {"!=":1} ] # shown unencodedwould be evaluated as
foo != 2 and foo != 1See https://metacpan.org/module/SQL::Abstract#WHERE-CLAUSES for more examples.
The me.* parameters are only passed-through in paging links.
Prefetching Related Objects
?prefetch=person,client_authThe resource may have 1-1 relationships with other resources. (E.g., a "belongs_to" relationship in DBIx::Class terminology.)
The relevant instances of related resources can be fetched and returned along with the requested resource by listing the relationships in a prefetch parameter.
For example: GET /ecosystems_people?prefetch=person,client_auth
{
"_links": { ... },
"_embedded": {
"ecosystems_people": [
{
"client_auth_id": "29",
"person_id": "8",
...
"_links": { ... },
"_embedded": {
"client_auth": { # embedded client_auth resourse
"id": 29
...
},
"person": { # embedded person resourse
"id": 8,
...
}
},
},
... # next ecosystems_people resource
]
}
}distinct
distinct=1Only return distinct results.
Currently this parameter requires that both the fields and order parameters are provided, and have identical values.
The results are returned in HAL format, i.e., as an array of objects in an _embedded field, but the objects themselves are not in HAL format, i.e. they don't have _links or _embedded elements.
PUT on Item
Update resource attributes using the JSON attribute values in the request body.
Embedded related resources can be supplied (if the Content-Type is application/hal+json).
Changes will be made in a single transaction.
Prefetch of related resources is supported.
TODO Enable use of the ETag header for optimistic locking?
PUT on Set
Not supported.
DELETE on Item
Delete the record.
DELETE on Set
Not supported.
POST on Item
Not supported.
POST on Set
Create a new resource in the set. Returns a 302 redirect with a Location header giving the URL of the newly created resource.
Any attributes that aren't specified in the POST data will be given the default values specified by the database schema.
The prefetch parameter can be used to request that the created resource (prefetch=self) and any related resources, be returned in the body of the response.
The rollback=1 parameter let's you rollback a POST to a set, e.g., for testing.
TBD check that only fields valid for GET have been supplied
Creating Related Resources
If the Content-Type is application/hal+json then related resources can be provided via the _embedded attribute. They will be created first and the corresponding key fields of the main resource will be set to the appropriate values before it's inserted. All database changes will happen in a single transaction.
For example, given a POST to /albums containing:
{
name: "album name",
artist_id: null, # optional
_embedded => {
artist => {
name: "artist name",
}
}
}The artist resource would be created first and its primary key would be used to set the artist_id field before that was created.
This process works recursively for any number of level and any number of relations at each level.
Errors
Error status responses should include a JSON object with at least these fields:
{
status: NNN,
message: "...",
}XXX Needs to be extended to be able to express errors related to specific attributes in the request.
The above is out of date. XXX review work on JSON media types for error reporting (I recall there's one that has adopted HAL).
Invoking Methods
To enable the execution of functionality not covered by the general HTTP mechanisms described above, it's possible to define resources that represent arbitary methods. These methods are executed by a POST request to the correponding resource. The body of the request contains the parameters to the method.
Currently a method can only be invoked on an item resource. The resource for the method call is simply the url of the item resource with '/invoke/:method' appended:
POST ~/ecosystems/:id/invoke/:methodThe request supports the same query parameters as the corresponding item resource.
Default Argument and Response Handling
Custom method resources can be defined which can perform any desired action, argument and response handling.
A default behaviour is provided to handle simple cases, and that is what is described here.
The named method is invoked on the item object specified by the item resource. In other words, the method is a method in the schema's Result class.
The POST request must use content-type of application/json and, if arguments are required, are specified via an 'args' element in the body JSON:
{ args => [ ... ] }The method is called in a scalar context.
If the method returns a DBIx::Class::Row object it is returned as a JSON hash.
If the method returns a DBIx::Class ResultSet object it is returned as a JSON array containing a hash for every row in the result set. There is no paging.
If the method returns any other kind of value it it returned as a JSON hash containing a single element 'result':
{ result: ... }(To avoid attempting to serialize objects, if the result is blessed then it's stringified.)
Note that this default behaviour is liable to change. If you want to make method calls like this you should define your own resource based on the one provided.
AUTHOR
Tim Bunce <Tim.Bunce@pobox.com>
COPYRIGHT AND LICENSE
This software is copyright (c) 2014 by Tim Bunce.
This is free software; you can redistribute it and/or modify it under the same terms as the Perl 5 programming language system itself.